Book Review: The Decline and Fall of the Roman Empire
When I begun my journey with Gibbon I knew two things: that he was one of the great stylists of the English language, and that he had a silly monocausal theory blaming Christianity for the fall of the Roman Empire.
Only one of those is true.
General Remarks
In the conduct of those monarchs we may trace the utmost lines of vice and virtue; the most exalted perfection and the meanest degeneracy of our own species.
Like the Iliad, like the pyramids, the Decline and Fall has an air of unreality. Even after experiencing these improbable productions at first hand, one still questions whether they really exist. Above all, the Decline and Fall is monumental—in size, scope, ambition, and style. It covers a singular subject, ranging over 14 centuries and half the globe, in a grand unified narrative centered around its main theme. Combining the features of the philosopher and the antiquarian, Gibbon can simultaneously present systematic theories of history, draw upon his vast knowledge to check them against the evidence, and impose order and coherence on an absurd amount of source material.
Why read something old and outdated when you can read contemporary historians? Gibbon did not have access to archaeological discoveries, placing him at a severe disadvantage. He was biased against Christianity and the Byzantines. And we have certainly gotten better at critically examining the sources:1 when Gibbon talks about armies of 400,000 on each side it is probably safe to divide those numbers by 10. But Gibbon isn't that outdated. His sources are our sources, he always went for the primary ones, and in the broad strokes he made no serious errors. In our age of specialization there is virtually nothing with the kind of scope and ambitious vision that are realized in the Decline and Fall.
Gibbon and his work are products of the Enlightenment in every way: liberty and reason, optimism, the "dark ages" and how they eventually set the stage for the modern world. Its main thesis is ultimately about the pernicious effects of tyranny on men and states—a triumphal victory lap for the freedom and science of the 18th century, as well as an investigation into their origins. It was produced in the middle of a golden age of British (and European) intellectual life: the first volume was published just three weeks before the Wealth of Nations! It would also not have been possible without continental thinkers like Voltaire and Montesquieu who heavily influenced Gibbon.
He had a solid foundation in the languages: excellent Greek, Latin, French, and English. As a young man he had already read all the great Roman literature, often more than once. To prepare for the Decline and Fall he acquired (at a cost of £3,000, approximately £230k in today's money) a personal library of some six or seven thousand volumes: every history book he could get his hands on, and many philosophical and theological tomes on top of that. This extraordinary erudition is displayed on every page, and is not limited to historians. Homer, for example, is mentioned 105 times (and Achilles 17).
The Decline and Fall is split into two parts: the first is tightly focused on the Romans and, despite moving at lightning speed, only manages to get to the year 640 by the end of volume 4. After that, Gibbon starts to roam freely to other peoples and skips over huge swathes of time (covering 8 centuries in 2 volumes), partly as a response to the degenerating quality of his sources. He tells a broader story about the external forces operating around the Byzantines (Islam, the crusades, the Mongols), the dark ages in Europe, and how they eventually led to the Renaissance. To explain Roman history, Gibbon has to explain the steppes. And to do that he has to go as far out as China.
Ultimately the focus is on the leaders, the wars, the grand events—spectacle. But the narrative is kept fresh and interesting with frequent digressions into theology, philosophy, jurisprudence, and anecdotes that illustrate national manners.

Style
Style is the image of character.
Style is the physiognomy of the mind.
Gibbon's style is monumental, active, Latinate, flamboyant, often epigrammatic.2 He is dense and rapid without being tiring, he is clever and amusing without degrading the dignity of his subject. He cannot be paraphrased. Gibbon has a love for spectacle, for the picturesque and the dramatic. Borges compares the Decline and Fall to a "crowded novel, whose protagonists are the generations of mankind, whose theater is the world". Nobody writes like him any more, which paradoxically makes the language feel both old and fresh.
His biggest influence was the grand and ironic Tacitus, who also wrote on the theme of decline, but unlike Tacitus Gibbon goes far beyond war and diplomacy. From his own time, he borrowed from Hume, William Robertson's History of Scotland, and above all Montesquieu. In fact the continental influence was so powerful that the Decline and Fall was almost written in French—this tragedy was prevented only by the intervention of David Hume, who convinced Gibbon to write it in English.3
Gibbon's sentences are long and balanced; his thought is dualistic and symmetrical, often based on comparisons or parallels between actions, characters, wars, and ages. He loves to expose contradictions within characters: Augustus is "at first the enemy, and at last the father" of Rome. He often goes for striking antitheses and juxtapositions, methods which allow him to instruct, pass judgment, and most importantly display the decline of the empire: he plays the old against the new, the particular against the general, the ideal against the pragmatic. Discussing the fall of Rome in 410, for instance, he starts with a very abstract contrast (depreciate advantages/magnify evils), then two historical comparisons, one backwards and the other forwards in time:
There exists in human nature a strong propensity to depreciate the advantages, and to magnify the evils, of the present times. Yet, when the first emotions had subsided, and a fair estimate was made of the real damage, the more learned and judicious contemporaries were forced to confess that infant Rome had formerly received more essential injury from the Gauls than she had now sustained from the Goths in her declining age. The experience of eleven centuries has enabled posterity to produce a much more singular parallel; and to affirm with confidence that the ravages of the Barbarians, whom Alaric had led from the banks of the Danube, were less destructive than the hostilities exercised by the troops of Charles the Fifth, a Catholic prince, who styled himself Emperor of the Romans.
At other times Gibbon likes to build up parallel clauses, from the small to the spectacular, from the general to the specific (or vice versa). Sometimes he ends with a jarring finale for surprise or humor:
The court of Arcadius indulged the zeal, applauded the eloquence, and neglected the advice of Synesius.
In this wonderful passage describing religion in the age of the Antonines, he uses an abccba ring structure for a triple juxtaposition, framing the discussion with the emperor and ending in a cynical arpeggio:
The policy of the emperors and the senate, as far as it concerned religion, was happily seconded by the reflections of the enlightened, and by the habits of the superstitious, part of their subjects. The various modes of worship which prevailed in the Roman world were all considered by the people as equally true; by the philosopher as equally false; and by the magistrate as equally useful.

"Every writer creates his own precursors. His work modifies our conception of the past, as it will modify the future", Borges writes, and it is impossible not to think of him when reading Gibbon. Take this sentence on Timur, for example: "the amusement of his leisure hours was the game of chess, which he improved or corrupted with new refinements." Improved or corrupted! When motives are unclear, Gibbon will revel in the ambiguity, presenting two options (one noble, the other base) and letting the reader decide: "the piety or the avarice", "the gratitude or ambition".
Virtues and vices are anthropomorphized and given an objective, independent existence. Ambition, greed, hope, and valour direct monarchs as if they were puppets.
Vanity might applaud the elevation of a French emperor of Constantinople; but prudence must pity, rather than envy, his treacherous and imaginary greatness.
His [Alexius] prudence, or his pride, was content with extorting from the French princes an oath of homage and fidelity.
Perhaps the most amusing aspect of his style is the heavy use of irony (another similarity to Tacitus, though Gibbon claimed he learned it from Pascal's Lettres provinciales).4 It was particularly useful when writing about religious matters, as it allowed him to defend his writing as orthodox when it was actually mocking the church, especially on the question of miracles which Gibon pursued relentlessly:
The miraculous cure of diseases of the most inveterate or even præternatural kind, can no longer occasion any surprise when we recollect that in the days of Irenæus, about the end of the second century, the resurrection of the dead was very far from being esteemed an uncommon event.
It may seem somewhat remarkable that Bernard of Clairvaux, who records so many miracles of his friend St. Malachi, never takes any notice of his own, which, in their turn, however, are carefully related by his companions and disciples.
But how shall we excuse the supine inattention of the Pagan and philosophic world to those evidences which were presented by the hand of Omnipotence, not to their reason, but to their senses? During the age of Christ, of his apostles, and of their first disciples, the doctrine which they preached was confirmed by innumerable prodigies. The lame walked, the blind saw, the sick were healed, the dead were raised, dæmons were expelled, and the laws of Nature were frequently suspended for the benefit of the church. But the sages of Greece and Rome turned aside from the awful spectacle, and, pursuing the ordinary occupations of life and study, appeared unconscious of any alterations in the moral or physical government of the world.
There is also a second Gibbon, the Gibbon of the footnotes. He is freer, wittier,5 sometimes grotesque or obscene. Carlyle, in a letter to his future wife, recommended the book but warned her to never look at the notes, for "they are often quite abominable". The notes offer a great contrast, a refreshing oasis where one can take a rest from the main narrative, sit down next to Gibbon, and laugh along with him at the follies of men and empires.
He was not without his detractors though. Coleridge felt Gibbon got the causes completely wrong (he thought the key was the imperial character destroying the national character), and that the spectacle overwhelmed the more important but less exciting aspects of history:
He takes notice of nothing but what may produce an effect; he skips on from eminence to eminence, without ever taking you through the valleys between: in fact, his work is little else but a disguised collection of all the splendid anecdotes which he could find in any book concerning any persons or nations from the Antonines to the capture of Constantinople.
He's not entirely wrong, but it feels unfair that he wanted Gibbon to write a completely different type of history. As long as you don't go in expecting Braudel, you won't be disappointed.

Christianity
The fierce and partial writers of the times, ascribing all virtue to themselves, and imputing all guilt to their adversaries, have painted the battle of the angels and dæmons. Our calmer reason will reject such pure and perfect monsters of vice or sanctity, and will impute an equal, or at least an indiscriminate, measure of good and evil to the hostile sectaries, who assumed and bestowed the appellations of orthodox and heretics. They had been educated in the same religion, and the same civil society. Their hopes and fears in the present, or in a future, life were balanced in the same proportion. On either side, the error might be innocent, the faith sincere, the practice meritorious or corrupt. Their passions were excited by similar objects; and they might alternately abuse the favour of the court, or of the people. The metaphysical opinions of the Athanasians and the Arians could not influence their moral character; and they were alike actuated by the intolerant spirit which has been extracted from the pure and simple maxims of the gospel.
Gibbon's greatest innovation also drew the most fervent attacks: the choice to write a history of the church from a purely secular perspective. To do this, in the infamous 15th and 16th chapters of the first volume he put aside the "primary causes" of Christianity (the supernatural ones), and instead wrote only about the "secondary causes": persons, policies, battles between sects, the spread of the faith across the Roman populace.
Despite all the irony, the Decline and Fall is not an anti-religious polemic by any stretch of the imagination; while Gibbon was certainly an enlightenment skeptic, he was no extremist. Voltaire, he thought, "was a bigot, an intolerant bigot." In fact Gibbon's anti-Christian bias reveals itself in peculiar ways, like his strong pro-Islamic bias: where the Christians had corrupted the early religion with idols, saints, and incense,6 the Muslims maintained a purer faith, closer to the Deist ideas of the time.
Later volumes give more attention to the history of Christianity as it grows and eventually becomes the state religion following Constantine. We get to see the journey from a small cult of true believers, to the persecutions, to its final transformation into a corrupt organ tightly married to the state. And in all this, Gibbon delights in revealing the base motives hidden behind professions of Christian virtues.
There's also a lot of theological detail: Gibbon goes deep into controversies like Pelagianism, Arianism, and the Byzantine battles over icons (in a way, it was just a different form of civil war). He covers Christianity's philosophical connections to Platonism.7 Athanasius gets over 30 pages just for himself (and the role he played in the homoousion vs homoiousion battle): he led an eventful life, sometimes at the top of the world, widely admired and respected, at other times exiled (5 exiles by 4 different emperors) or hiding out in the middle of nowhere. In general the persecution of one sect of Christianity by another was a feature from very early on, and often brutal.
In line with his views on liberty and reason in the political sphere, what Gibbon disliked most about Christianity was the fanaticism that magnified the narcissism of small differences to apocalyptic proportions, exhausted the empire through yet more internecine conflict, and stultified the mind by the totalitarian enforcement of a doubtful orthodoxy.

Causes
Causality has always been a fraught topic. Today one often encounters historians making bizarre claims against counterfactuals and causal analysis while at the same time assigning "importance" to this or that factor. On the other hand you have economic historians and cliometricians who are doing quantitative big history with questionable causal models.
The debate was similar in the 18th century. The first thing Gibbon ever published was an essay titled Essai sur l'étude de la littérature (written at the age of 24). In it, he covers a bewildering array of topics, but it has two sections dedicated to historical theories which give us a window into his approach. On one side he places the "philosophic" historians (like Voltaire or Vico) who are enamoured with a single big idea to the detriment of the facts:8
The shining genius is dazzled by his own conjectures, and sacrifices his freedom to his hypotheses. From such a disposition do systems originate.
And on the opposite extreme we have those who credit only chance and contingency:
They have banished art from the moral world, and have replaced it by chance. According to them, weak mortals act only by caprice. An empire is established by the frenzy of a maniac; it is destroyed by the weakness of a woman.
Instead, Gibbon proposes to chart a middle course, taking into account both general causes and particular circumstances. He lays out an abstract plan for a grand work:
How vast a field lies open to my reflections! In the hands of a Montesquieu the theory of general causes would form a philosophic history of mankind. He would show us their dominion over the grandeur and fall of empires, borrowing successively the appearance , of fortune, prudence, courage, and weakness; acting without the concurrence of particular causes, and sometimes even triumphing over them. Superior to the love of his own systems, the wise man‘s last passion, he would easily perceive, that notwithstanding the wide extent of these causes, their effects are, nevertheless, limited, and that they are principally seen in those general events, whose slow but sure influence changes the aspect of the world without its being possible to mark the epoch of the change.
And that is exactly what he wrote. The Decline and Fall tends to foreground uncertainty over large, singular explanatory causes, while simultaneously trying to explain the "general events" behind the "revolutions of society", and trying to identify the "secret springs of action which impel the blind and capricious passions" of the people.
For my own tastes, I would say Gibbon erred on the side of too little systematizing, but by refusing to bet the whole work on a single idea he made it immortal. If the Decline and Fall was a thesis arguing for this or that specific cause, then our judgment of the work would hinge on the merits of that theory. By refusing to take a stand, Gibbon guaranteed his longevity.
The Fall of the Roman Empire
Prosperity ripened the principle of decay; the causes of destruction multiplied with the extent of conquest; and, as soon as time or accident had removed the artificial supports, the stupendous fabric yielded to the pressure of its own weight. The story of its ruin is simple and obvious; and, instead of inquiring why the Roman empire was destroyed, we should rather be surprised that it had subsisted so long.
At the highest level there are two types of causes behind the fall of the Roman empire: internal and external. The history of Europe over Gibbon's timeline is the history of a continuous stream of invasions from the North and the East, either repulsed by the superior organization of civilized states, or victorious due to their warlike nature. If I had to pick a contemporary companion to Gibbon (not in style but in content), it would be this quantitative history paper by Currie, Turchin, Turner & Gavrilets: Duration of agriculture and distance from the steppe predict the evolution of large-scale human societies in Afro-Eurasia. It's about the interplay between the steppe and the regions around it, and makes two basic claims: 1) the closer to the steppe, the greater the "imperial density", and 2) distance from the steppe became more important over time.
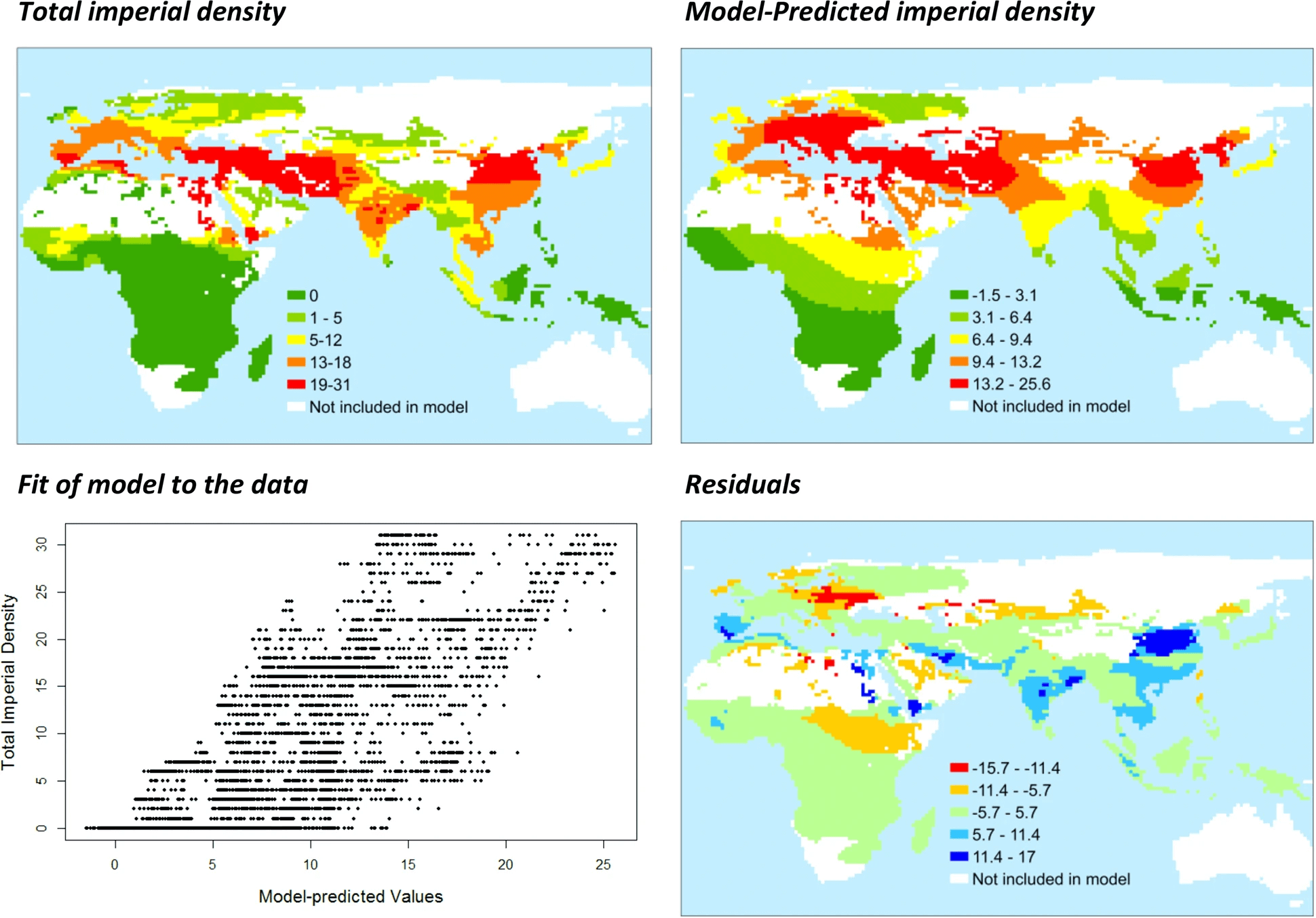
In the end, Gibbon treats the external danger as a kind of inevitable force of nature which the civilized societies must either defend against or perish. Which brings us to the internal causes.
Gibbon examines a wide variety of theories, but never brings everything together into a single coherent system. At the most abstract level he blames the tyranny of an overbearing and unstable monarchy. More specifically, there are two broad classes of causes, both of which are downstream from the imperial form of government: 1) the dynamics of the army, and 2) a broader societal decline caused by excess comfort and lack of freedom. But the factors all feed into each other and it's very difficult to separate the chickens from the eggs.
The initial dysfunction of the Empire is relatively clear: the emperors become dependent on the army which causes all sorts of trouble. As Romans are no longer willing to bear arms, the legions are filled with recruits from conquered provinces and the Empire is essentially conquered from the inside by Illyrians (starting with Decius in the mid-3rdC). The final event in this process was Constantine's army reforms, splitting the legions into mobile legions (comitatenses) and permanent garrisons (limitanei). On top of this you have an endless series of civil wars, which again have their source in the army (as well as the lack of clear succession): prospective Emperors could promise huge bribes, the troops felt no kinship with anyone else in the Empire, and the immense distances involved made central control extremely difficult.
As time went on, the Roman state tended toward the strategy of a stationary bandit, maximizing tax revenues and using them to pay the army and the bureaucracy. Scheidel estimates that the army took up 60% of expenditures, though at the same time low-level soldiers were not paid very well.9 By the 6th century, many Italians preferred the barbarians to being "liberated" by the Byzantines.
But this is perhaps putting too-rational a spin on things, as the state not only failed to provide security for its subjects but also for itself: the internal dysfunction ultimately destroyed both the bandit and his subjects. The system had no margins, no flexibility, limited possibilities for intertemporal substitution, and depended heavily on surpluses from mines in Spain and the wealthier provinces (Gaul, Syria, Egypt). It could only survive as long as conditions were stable and external pressures limited.10
Direct comparisons to our time are not worthwhile (the army taking over and paying itself 60% of revenues is unlikely today), but could be interesting if we look at it as an instance of a more general pattern in which states tend toward revenue maximization over the long run. As I was reading Gibbon I kept thinking of Mancur Olson's The Rise and Decline of Nations, in which he argues that states accumulate cruft in the form of cartelistic/public choice behaviors which inevitably grow too large and cause a collapse. I don't want to simplify this too much, as there are tons of factors going into it (for example, if principal-agent problems in tax collection are too bad, rulers might not want to maximize revenues), but I do think there's something to this idea. On the other hand perhaps the Republic offers a better parallel than the Empire.
There are also some theories supported by modern historians that Gibbon doesn't even consider. For example, some believe that the Plague of Justinian played a key role in the fall of Rome (though other modern historians disagree), while Gibbon barely mentions it. He pays scant attention to demographics, the falling output of Iberian silver mines, or the endless problems with debased (or non-existent) coinage.
Let's take a look at some specifics, in Gibbon's own words.
Army
Praetorians & non-Italian soldiers
Following the Year of the Five Emperors, Severus comes out on top; he rewards the troops copiously and remakes the Praetorians, who then effectively become the true power behind the emperor:
The Prætorians, who murdered their emperor and sold the empire, had received the just punishment of their treason; but the necessary, though dangerous, institution of guards was soon restored on a new model by Severus, and increased to four times the ancient number. Formerly these troops had been recruited in Italy; and, as the adjacent provinces gradually imbibed the softer manners of Rome, the levies were extended to Macedonia, Noricum and Spain. In the room of these elegant troops, better adapted to the pomp of courts than to the uses of war, it was established by Severus, that, from all the legions of the frontiers, the soldiers most distinguished for strength, valour, and fidelity, should be occasionally draughted, and promoted, as an honour and reward, into the more eligible service of the guards. By this new institution, the Italian youth were diverted from the exercise of arms, and the capital was terrified by the strange aspect and manners of a multitude of barbarians. But Severus flattered himself that the legions would consider these chosen Prætorians as the representatives of the whole military order; and that the present aid of fifty thousand men, superior in arms and appointments to any force that could be brought into the field against them, would for ever crush the hopes of rebellion, and secure the empire to himself and his posterity.
The command of these favoured and formidable troops soon became the first office of the empire. As the government degenerated into military despotism, the Prætorian præfect, who in his origin had been a simple captain of the guards, was placed, not only at the head of the army, but of the finances, and even of the law. In every department of administration, he represented the person, and exercised the authority, of the emperor. The first præfect who enjoyed and abused this immense power was Plautianus, the favourite minister of Severus. His reign lasted above ten years, till the marriage of his daughter with the eldest son of the emperor, which seemed to assure his fortune, proved the occasion of his ruin. The animosities of the palace, by irritating the ambition and alarming the fears of Plautianus, threatened to produce a revolution, and obliged the emperor, who still loved him, to consent with reluctance to his death. After the fall of Plautianus, an eminent lawyer, the celebrated Papinian, was appointed to execute the motley office of Prætorian præfect.
Army power
As the army grew more powerful, it extracted more and more concessions from the emperors; it also grew less disciplined and less capable of defending the empire.
The victorious legions, who, in distant wars, acquired the vices of strangers and mercenaries, first oppressed the freedom of the republic, and afterwards violated the majesty of the purple. The emperors, anxious for their personal safety and the public peace, were reduced to the base expedient of corrupting the discipline which rendered them alike formidable to their sovereign and to the enemy; the vigour of the military government was relaxed, and finally dissolved, by the partial institutions of Constantine; and the Roman world was overwhelmed by a deluge of Barbarians.
Civil wars
The empire was extraordinarily difficult to control from the center, and both soldiers and ambitious generals abused that lack of control to launch civil wars. In the third century there was a new one almost every three years. The immense waste of resources and manpower naturally weakened the empire against external threats.
The rapid and perpetual transitions from the cottage to the throne, and from the throne to the grave, might have amused an indifferent philosopher, were it possible for a philosopher to remain indifferent amidst the general calamities of human kind. The election of these precarious emperors, their power and their death, were equally destructive to their subjects and adherents. The price of their fatal elevation was instantly discharged to the troops by an immense donative drawn from the bowels of the exhausted people. However virtuous was their character, however pure their intentions, they found themselves reduced to the hard necessity of supporting their usurpation by frequent acts of rapine and cruelty. When they fell, they involved armies and provinces in their fall. There is still extant a most savage mandate from Gallienus to one of his ministers, after the suppression of Ingenuus, who had assumed the purple in Illyricum. “It is not enough,” says that soft but inhuman prince, “that you exterminate such as have appeared in arms: the chance of battle might have served me as effectually. The male sex of every age must be extirpated; provided that, in the execution of the children and old men, you can contrive means to save our reputation. Let every one die who has dropt an expression, who has entertained a thought, against me, against me, the son of Valerian, the father and brother of so many princes.58 Remember that Ingenuus was made emperor: tear, kill, hew in pieces. I write to you with my own hand, and would inspire you with my own feelings.” Whilst the public forces of the state were dissipated in private quarrels, the defenceless provinces lay exposed to every invader. The bravest usurpers were compelled by the perplexity of their situation to conclude ignominious treaties with the common enemy, to purchase with oppressive tributes the neutrality or services of the barbarians, and to introduce hostile and independent nations into the heart of the Roman monarchy.
Constantine's army reforms
The biggest criticism Gibbon has for Constantine is not his toleration of and conversion to Christianity, but rather his reforms of the army.
the feeble policy of Constantine and his successors armed and instructed, for the ruin of the empire, the rude valour of the Barbarian mercenaries.
Of all the causes for the fall, this is the one Gibbon puts the greatest emphasis on, so I will quote him liberally.
The memory of Constantine has been deservedly censured for another innovation, which corrupted military discipline and prepared the ruin of the empire. The nineteen years which preceded his final victory over Licinius had been a period of licence and intestine war. The rivals who contended for the possession of the Roman world had withdrawn the greatest part of their forces from the guard of the general frontier; and the principal cities which formed the boundary of their respective dominions were filled with soldiers, who considered their countrymen as their most implacable enemies. [...] From the reign of Constantine, a popular and even legal distinction was admitted between the Palatines and the Borderers; the troops of the court as they were improperly styled, and the troops of the frontier. The former, elevated by the superiority of their pay and privileges, were permitted, except in the extraordinary emergencies of war, to occupy their tranquil stations in the heart of the provinces. The most flourishing cities were oppressed by the intolerable weight of quarters. The soldiers insensibly forgot the virtues of their profession, and contracted only the vices of civil life. They were either degraded by the industry of mechanic trades, or enervated by the luxury of baths and theatres. They soon became careless of their martial exercises, curious in their diet and apparel; and, while they inspired terror to the subjects of the empire, they trembled at the hostile approach of the Barbarians. The chain of fortifications which Diocletian and his colleagues had extended along the banks of the great rivers was no longer maintained with the same care or defended with the same vigilance. The numbers which still remained under the name of the troops of the frontier might be sufficient for the ordinary defence. But their spirit was degraded by the humiliating reflection that they who were exposed to the hardships and dangers of a perpetual warfare were rewarded only with about two-thirds of the pay and emoluments which were lavished on the troops of the court. Even the bands or legions that were raised the nearest to the level of those unworthy favourites were in some measure disgraced by the title of honour which they were allowed to assume. It was in vain that Constantine repeated the most dreadful menaces of fire and sword against the Borderers who should dare to desert their colours, to connive at the inroads of the Barbarians, or to participate in the spoil. The mischiefs which flow from injudicious counsels are seldom removed by the application of partial severities; and, though succeeding princes laboured to restore the strength and numbers of the frontier garrisons, the empire, till the last moment of its dissolution, continued to languish under the mortal wound which had been so rashly or so weakly inflicted by the hand of Constantine.
The same timid policy, of dividing whatever is united, of reducing whatever is eminent, of dreading every active power, and of expecting that the most feeble will prove the most obedient, seems to persuade the institutions of several princes, and particularly those of Constantine. The martial pride of the legions, whose victorious camps had so often been the scene of rebellion, was nourished by the memory of their past exploits and the consciousness of their actual strength. As long as they maintained their ancient establishment of six thousand men, they subsisted, under the reign of Diocletian, each of them singly, a visible and important object in the military history of the Roman empire. A few years afterwards these gigantic bodies were shrunk to a very diminutive size; and, when seven legions, with some auxiliaries, defended the city of Amida against the Persians, the total garrison, with the inhabitants of both sexes, and the peasants of the deserted country, did not exceed the number of twenty thousand persons. From this fact, and from similar examples, there is reason to believe that the constitution of the legionary troops, to which they partly owed their valour and discipline, was dissolved by Constantine; and that the bands of Roman infantry, which still assumed the same names and the same honours, consisted only of one thousand or fifteen hundred men. The conspiracy of so many separate detachments, each of which was awed by the sense of its own weakness, could easily be checked; and the successors of Constantine might indulge their love of ostentation, by issuing their orders to one hundred and thirty-two legions, inscribed on the muster-roll of their numerous armies. The remainder of their troops was distributed into several hundred cohorts of infantry, and squadrons of cavalry. Their arms, and titles, and ensigns were calculated to inspire terror, and to display the variety of nations who marched under the Imperial standard. And not a vestige was left of that severe simplicity which, in the ages of freedom and victory, had distinguished the line of battle of a Roman army from the confused host of an Asiatic monarch. A more particular enumeration, drawn from the Notitia, might exercise the diligence of an antiquary; but the historian will content himself with observing that the number of permanent stations or garrisons established on the frontiers of the empire amounted to five hundred and eighty-three; and that, under the successors of Constantine, the complete force of the military establishment was computed at six hundred and forty-five thousand soldiers. An effort so prodigious surpassed the wants of a more ancient, and the faculties of a later, period.
In the various states of society, armies are recruited from very different motives. Barbarians are urged by the love of war; the citizens of a free republic may be prompted by a principle of duty; the subjects, or at least the nobles, of a monarchy are animated by a sentiment of honour; but the timid and luxurious inhabitants of a declining empire must be allured into the service by the hopes of profit, or compelled by the dread of punishment. The resources of the Roman treasury were exhausted by the increase of pay, by the repetition of donatives, and by the invention of new emoluments and indulgences, which, in the opinion of the provincial youth, might compensate the hardships and dangers of a military life. Yet, although the stature was lowered, although slaves, at least by a tacit connivance, were indiscriminately received into the ranks, the insurmountable difficulty of procuring a regular and adequate supply of volunteers obliged the emperors to adopt more effectual and coercive methods. The lands bestowed on the veterans, as the free reward of their valour, were henceforward granted under a condition, which contains the first rudiments of the feudal tenures; that their sons, who succeeded to the inheritance, should devote themselves to the profession of arms, as soon as they attained the age of manhood; and their cowardly refusal was punished by the loss of honour, of fortune, or even of life. But, as the annual growth of the sons of the veterans bore a very small proportion to the demands of the service, levies of men were frequently required from the provinces, and every proprietor was obliged either to take up arms, or to procure a substitute, or to purchase his exemption by the payment of a heavy fine. The sum of forty-two pieces of gold, to which it was reduced, ascertains the exorbitant price of volunteers and the reluctance with which the government admitted of this alternative. Such was the horror for the profession of a soldier which had affected the minds of the degenerate Romans that many of the youth of Italy and the provinces chose to cut off the fingers of their right hand to escape from being pressed into the service; and this strange expedient was so commonly practised as to deserve the severe animadversion of the laws and a peculiar name in the Latin language.
The introduction of Barbarians into the Roman armies became every day more universal, more necessary, and more fatal. The most daring of the Scythians, of the Goths, and of the Germans, who delighted in war, and who found it more profitable to defend than to ravage the provinces, were enrolled, not only in the auxiliaries of their respective nations, but in the legions themselves, and among the most distinguished of the Palatine troops. As they freely mingled with the subjects of the empire, they gradually learned to despise their manners and to imitate their arts. They abjured the implicit reverence which the pride of Rome had exacted from their ignorance, while they acquired the knowledge and possession of those advantages by which alone she supported her declining greatness. The Barbarian soldiers who displayed any military talents were advanced, without exception, to the most important commands; and the names of the tribunes, of the counts and dukes, and of the generals themselves, betray a foreign origin, which they no longer condescended to disguise. They were often entrusted with the conduct of a war against their countrymen; and, though most of them preferred the ties of allegiance to those of blood, they did not always avoid the guilt, or at least the suspicion, of holding a treasonable correspondence with the enemy, of inviting his invasion, or of sparing his retreat. The camps and the palace of the son of Constantine were governed by the powerful faction of the Franks, who preserved the strictest connexion with each other and with their country, and who resented every personal affront as a national indignity. When the tyrant Caligula was suspected of an intention to invest a very extraordinary candidate with the consular robes, the sacrilegious profanation would have scarcely excited less astonishment, if, instead of a horse, the noblest chieftain of Germany or Britain had been the object of his choice. The revolution of three centuries had produced so remarkable a change in the prejudices of the people that, with the public approbation, Constantine showed his successors the example of bestowing the honours of the consulship on the Barbarians who, by their merit and services, had deserved to be ranked among the first of the Romans.81 But as these hardy veterans, who had been educated in the ignorance or contempt of the laws, were incapable of exercising any civil offices, the powers of the human mind were contracted by the irreconcilable separation of talents as well as of professions. The accomplished citizens of the Greek and Roman republics, whose characters could adapt themselves to the bar, the senate, the camp, or the schools, had learned to write, to speak, and to act, with the same spirit, and with equal abilities.

General Internal Decay
The idea that oppressive monarchies are unsuitable for the flourishing of genius recurs often.
This long peace, and the uniform government of the Romans, introduced a slow and secret poison into the vitals of the empire. The minds of men were gradually reduced to the same level, the fire of genius was extinguished, and even the military spirit evaporated. [...] They received laws and governors from the will of their sovereign, and trusted for their defence to a mercenary army. The posterity of their boldest leaders was contented with the rank of citizens and subjects. The most aspiring spirits resorted to the court or standard of the emperors; and the deserted provinces, deprived of political strength or union, insensibly sunk into the languid indifference of private life.
Decline in warlike nature of Romans
Which brings us to the fluffier factors. One of the most frequent leitmotifs in the Decline and Fall is a barbarian nation conquering civilized one, taking up their way of life, and quickly becoming weak and feminized. It happens to the Vandals, the Mongols, the Timurid empire, etc. Comfort, profit, city living, the arts, fine wine—little more than secret poisons, weakening civilizations and making them easy pray for the next round of barbarian invaders. Here is how Gibbon describes the Yuan dynasty:
The northern, and by degrees the southern, empire acquiesced in the government of Cublai, the lieutenant and afterwards the successor of Mangou; and the nation was loyal to a prince who had been educated in the manners of China. He restored the forms of her venerable constitution; and the victors submitted to the laws, the fashions, and even the prejudices of the vanquished people. The peaceful triumph, which has been more than once repeated, may be ascribed, in a great measure, to the numbers and servitude of the Chinese. The Mogul army was dissolved in a vast and populous country; and their emperors adopted with pleasure a political system which gives to the prince the solid substance of despotism and leaves to the subject the empty names of philosophy, freedom, and filial obedience. Under the reign of Cublai, letters and commerce, peace and justice, were restored; the great canal of five hundred miles was opened from Nankin to the capital; he fixed his residence at Pekin, and displayed in his court the magnificence of the greatest monarch of Asia. Yet this learned prince declined from the pure and simple religion of his great ancestor; he sacrificed to the idol Fo; and his blind attachment to the lamas of Thibet and the bonzes of China provoked the censure of the disciples of Confucius. His successors polluted the palace with a crowd of eunuchs, physicians, and astrologers, while thirteen millions of their subjects were consumed in the provinces by famine. One hundred and forty years after the death of Zingis, his degenerate race, the dynasty of the Yuen, was expelled by a revolt of the native Chinese; and the Mogul emperors were lost in the oblivion of the desert.
Something like that applied to the Romans, too.
The feeble elegance of Italy and the internal provinces could no longer support the weight of arms. The hardy frontier of the Rhine and Danube still produced minds and bodies equal to the labours of the camp; but a perpetual series of wars had gradually diminished their numbers. The infrequency of marriage, and the ruin of agriculture, affected the principles of population, and not only destroyed the strength of the present, but intercepted the hope of future, generations.
The nation is dissolved under the empire, which lacks the necessary bonds to hold it together.
The empire of Rome was firmly established by the singular and perfect coalition of its members. The subject nations, resigning the hope, and even the wish, of independence, embraced the character of Roman citizens; and the provinces of the West were reluctantly torn by the Barbarians from the bosom of their mother-country. But this union was purchased by the loss of national freedom and military spirit; and the servile provinces, destitute of life and motion, expected their safety from the mercenary troops and governors, who were directed by the orders of a distant court.
Farmers vs steppe pastoralists
From the spacious highlands between China, Siberia, and the Caspian Sea, the tide of emigration and war has repeatedly been poured.
Those barbarians have to come from somewhere, of course. They come from the pastoral tribes in the steppes, a way of life more conducive to the production of warriors.
The thrones of Asia have been repeatedly overturned by the shepherds of the North; and their arms have spread terror and devastation over the most fertile and warlike countries of Europe. On this occasion, as well as on many others, the sober historian is forcibly awakened from a pleasing vision; and is compelled, with some reluctance, to confess that the pastoral manners which have been adorned with the fairest attributes of peace and innocence are much better adapted to the fierce and cruel habits of a military life.
This is a purely subjective impression on my part, based on virtually no evidence whatsoever (though it fits in well with the Currie et al. paper I mentioned earlier), but it seems like the steppe nomads got much better over time. The Scythians were kinda scary, the Goths were a bit more dangerous but only won because the Romans didn't have their shit together, the Huns were hardcore, and then Gengis and Timur just steamroll everything in their path with barely any resistance. How much of this is just down to weaker states on the defensive side? And where does Islam fit into this? I'm not sure. In the end the cycle of steppe invasions was ended by gunpowder, so Timur was as bad as it got.
Abdicating the responsibilities of freedom
The Romans got too comfortable in their success, pacified by bread & circuses, and were happy to give up their power and responsibility, ultimately leading to decay in Roman institutions. Gibbon comments on a new institution dreamed up by Honorius in the early 5th century, a kind of republican assembly:
If such an institution, which gave the people an interest in their own government, had been universally established by Trajan or the Antonines, the seeds of public wisdom and virtue might have been cherished and propagated in the empire of Rome. The privileges of the subject would have secured the throne of the monarch; the abuses of an arbitrary administration might have been prevented, in some degree, or corrected, by the interposition of these representative assemblies; and the country would have been defended against a foreign enemy by the arms of natives and freemen. Under the mild and generous influence of liberty, the Roman empire might have remained invincible and immortal; or, if its excessive magnitude and the instability of human affairs had opposed such perpetual continuance, its vital and constituent members might have separately preserved their vigour and independence. But in the decline of the empire, when every principle of health and life had been exhausted, the tardy application of this partial remedy was incapable of producing any important or salutary effects. The Emperor Honorius expresses his surprise that he must compel the reluctant provinces to accept a privilege which they should ardently have solicited. A fine of three or even five pounds of gold was imposed on the absent representatives; who seem to have declined this imaginary gift of a free constitution, as the last and most cruel insult of their oppressors.
Christianity
Finally, Gibbon did (partly) blame Christianity for the fall. His criticisms mostly focused on 1) monasteries operating as brain drains, 2) the cultural effects, and 3) the fanaticism and internal divisions caused by warring sects.
As the happiness of a future life is the great object of religion, we may hear, without surprise or scandal, that the introduction, or at least the abuse, of Christianity had some influence on the decline and fall of the Roman empire. The clergy successfully preached the doctrines of patience and pusillanimity; the active virtues of society were discouraged; and the last remains of military spirit were buried in the cloister; a large portion of public and private wealth was consecrated to the specious demands of charity and devotion; and the soldiers’ pay was lavished on the useless multitudes of both sexes, who could only plead the merits of abstinence and chastity. Faith, zeal, curiosity, and the more earthly passions of malice and ambition kindled the flame of theological discord; the church, and even the state, were distracted by religious factions, whose conflicts were sometimes bloody, and always implacable; the attention of the emperors was diverted from camps to synods; the Roman world was oppressed by a new species of tyranny; and the persecuted sects became the secret enemies of their country. Yet party-spirit, however pernicious or absurd, is a principle of union as well as of dissension. The bishops, from eighteen hundred pulpits, inculcated the duty of passive obedience to a lawful and orthodox sovereign; their frequent assemblies, and perpetual correspondence, maintained the communion of distant churches: and the benevolent temper of the gospel was strengthened, though confined, by the spiritual alliance of the Catholics. The sacred indolence of the monks was devoutly embraced by a servile and effeminate age; but, if superstition had not afforded a decent retreat, the same vices would have tempted the unworthy Romans to desert, from baser motives, the standard of the republic. Religious precepts are easily obeyed, which indulge and sanctify the natural inclinations of their votaries; but the pure and genuine influence of Christianity may be traced in its beneficial, though imperfect, effects on the Barbarian proselytes of the North. If the decline of the Roman empire was hastened by the conversion of Constantine, his victorious religion broke the violence of the fall, and mollified the ferocious temper of the conquerors.
He viewed religious tyranny simply as a different type of loss of freedom, with the same effects. On the monasteries:
The freedom of the mind, the source of every generous and rational sentiment, was destroyed by the habits of credulity and submission; and the monk, contracting the vices of a slave, devoutly followed the faith and passions of his ecclesiastical tyrant. The peace of the Eastern church was invaded by a swarm of fanatics, incapable of fear, or reason, or humanity; and the Imperial troops acknowledged, without shame, that they were much less apprehensive of an encounter with the fiercest Barbarians.

Fin
In the end, is it worth the effort? Absolutely. I started reading the Decline and Fall on January 1, 2020. 363 days and nearly 4000 pages later I was sad to reach the end. I would gladly have kept going into the Renaissance and beyond. I recommend you follow a similar pace: 10 or 20 pages in bed every night, you don't want to rush through it. Gibbon will give you something new to talk about every day.
As always with these types of books, I recommend the Everyman's Library edition: fantastic quality and dirt cheap, especially if you get a used copy (my own set bears the library markings of the Kings of Wessex school in Cheddar, Somerset—apparently Gibbon is out of favor with schoolboys these days). The only downside is that you don't get the Piranesi illustrations which are included in some other editions (like the Heritage).
Highlights will come in a separate post in a few days.
- 1.Gibbon missed the train on the German source criticism that was taking off at the time. ↩
- 2.Iggy Pop called it "rich and complete". ↩
- 3.He argued that, thanks to the American colonies, English would outlive French like Latin outlived Greek! ↩
- 4.Byron called him "the lord of irony" in his wonderful little poem on Gibbon and Voltaire:
The other, deep and slow, exhausting thought,
And hiving wisdom with each studious year,
In meditation dwelt, with learning wrought,
And shaped his weapon with an edge severe,
Sapping a solemn creed with solemn sneer:
The lord of irony,—that master-spell,
Which stung his foes to wrath, which grew from fear,
And doomed him to the zealot’s ready hell,
Which answers to all doubts so eloquently well. ↩ - 5.He was a contemporary of Samuel Johnson, after all. ↩
- 6."The smoke of incense, the perfume of flowers, and the glare of lamps and tapers, which diffused, at noonday, a gaudy, superfluous, and a sacrilegious light." ↩
- 7.Logos and its connection to Arianism. ↩
- 8.Isaiah Berlin's "hedgehogs", basically. ↩
- 9.There's an argument to be made that low pay for soldiers (combined with a lack of opportunities for plunder once expansion ended) contributed to the shift of army demographics from Italy to the provinces. ↩
- 10.I like how Luttwak puts it: "The empire merely enjoyed modest economies-of-scale advantages, which were not large enough to compensate for much administrative inefficiency, internal strife, and bureaucratic venality. And because inefficiency, strife, and venality could not be sufficiently contained, the empire was losing its value to its subjects: it still demanded large tax payments but offered less and less security. In the end, as the empire’s ability to extract taxes persistently exceeded its ability to protect its subjects and their property, the arrival of the barbarians could even become some sort of solution." ↩















{kind=link}