Two Paths to the Future
[[ ]] Level-1 or world space is an anthropomorphically scaled, predominantly vision-configured, massively multi-slotted reality system that is obsolescing very rapidly.
Garbage time is running out.
Can what is playing you make it to level-2?
The history of the world is a history of s-curves stacked on top of each other. Here's one of my favorite charts, showing growth in how much cutting edge could be produced from 1kg of flint during the stone age:1
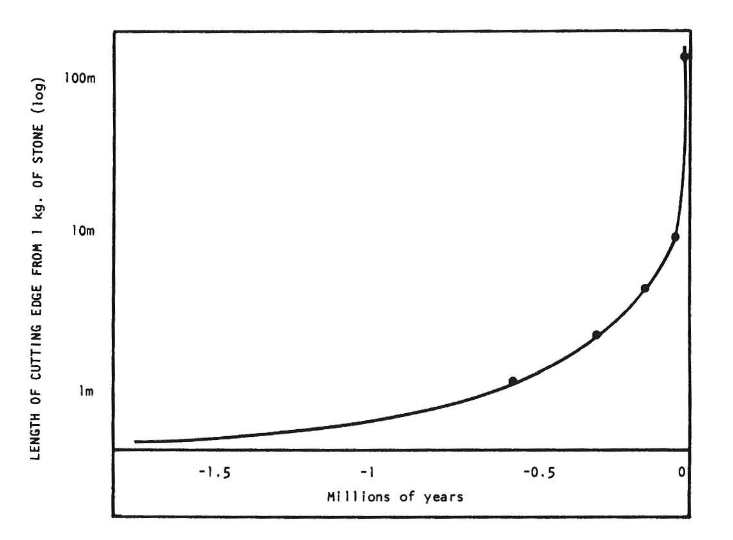
Note the logarithmic y-axis—the growth is not exponential but hyperbolic! Of course what appears to be a singularity is really the lower half of an s-curve, but that was enough to trigger a paradigm shift to a new, higher curve: bronze. The stone-age singularity was the end of stone. Can what is playing you make it to level-2?
Where are we today? It's hard to say without the benefit of hindsight, but it sure feels like the upper half of an s-curve. Things are decelerating: economic growth is falling, fertility is cratering, and IQ shredders are quickly using up the finite biological substrate necessary to sustain our upward path. The world of 2020 is more or less the same as the world of 1920. We are richer, have better technology, but the fundamentals are quite similar: we're on the same curve. All we're doing is getting more blades from our flint.
The world of 2120 is going to be radically different. In exactly what way I cannot say, any more than a peasant in 1500 could predict the specifics of the industrial revolution. But it almost certainly involves unprecedented levels of growth as the constraints of the old paradigm are dissolved under the new one. One corollary to this view is that our long-term concerns (global warming, dysgenics, aging societies) are only relevant to the extent that they affect the arrival of the next paradigm.
There are two paths to the future: silicon, and DNA. Whichever comes first will determine how things play out. The response to the coronavirus pandemic has shown that current structures are doomed to fail against a serious adversary: if we want to have a chance against silicon, we need better people. That is why I think any AI "control" strategy not predicated on transhumanism is unserious.2
Our neolithic forefathers could not have divined the metallurgical destiny of their descendants, but today, perhaps for the first time in universal history, we can catch a glimpse of the next paradigm before it arrives. If you point your telescope in exactly the right direction and squint really hard, you can just make out the letters: "YOU'RE FUCKED".
Artificial Intelligence
Nothing human makes it out of the near-future.
There are two components to forecasting the emergence of superhuman AI. One is easy to predict: how much computational power we will have.3 The other is very difficult to predict: how much computational power will be required. Good forecasts are either based on past data, or generalization from theories constructed from past data. Because of their novelty, paradigm shifts are difficult to predict. We're in uncharted waters here. But there are two sources of information we can use: biological intelligence (brains, human or otherwise), and progress in the limited forms of artificial intelligence we have created thus far.4
ML progress
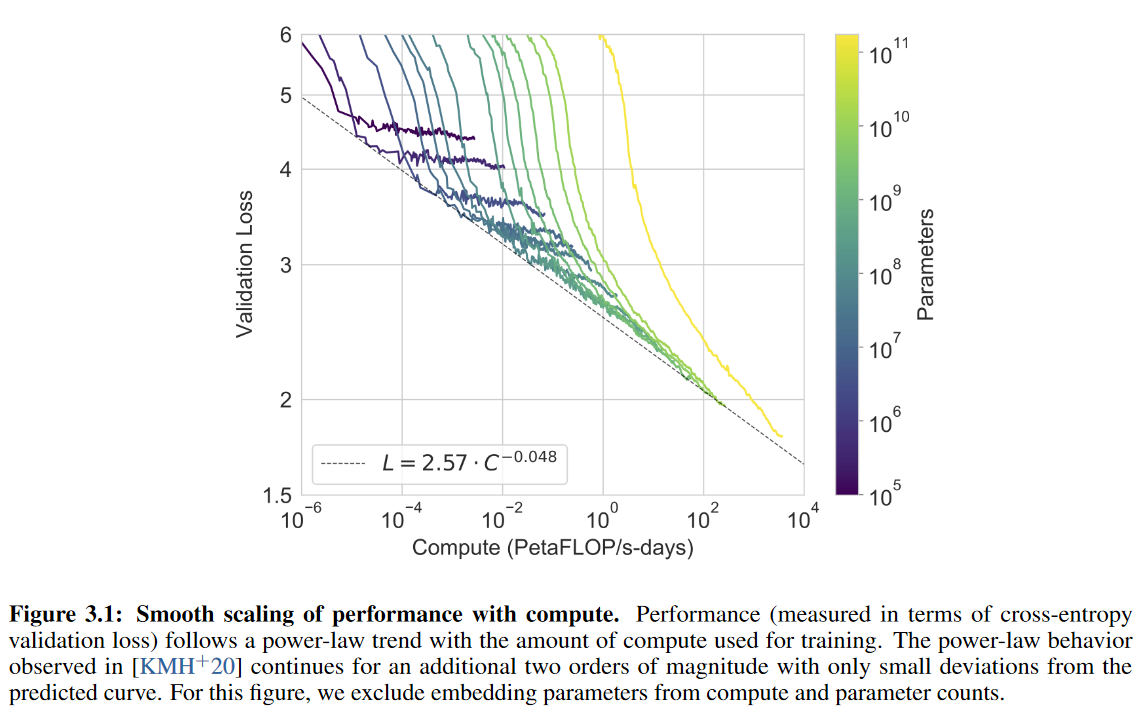
GPT-3 forced me to start taking AI concerns seriously. Two features make GPT-3 a scary sign of what's to come: scaling, and meta-learning. Scaling refers to gains in performance from increasing the number of parameters in a model. Here's a chart from the GPT-3 paper:
Meta-learning refers to the ability of a model to learn how to solve novel problems. GPT-3 was trained purely on next-word prediction, but developed a wide array of surprising problem-solving abilities, including translation, programming, arithmetic, literary style transfer, and SAT analogies. Here's another GPT-3 chart:
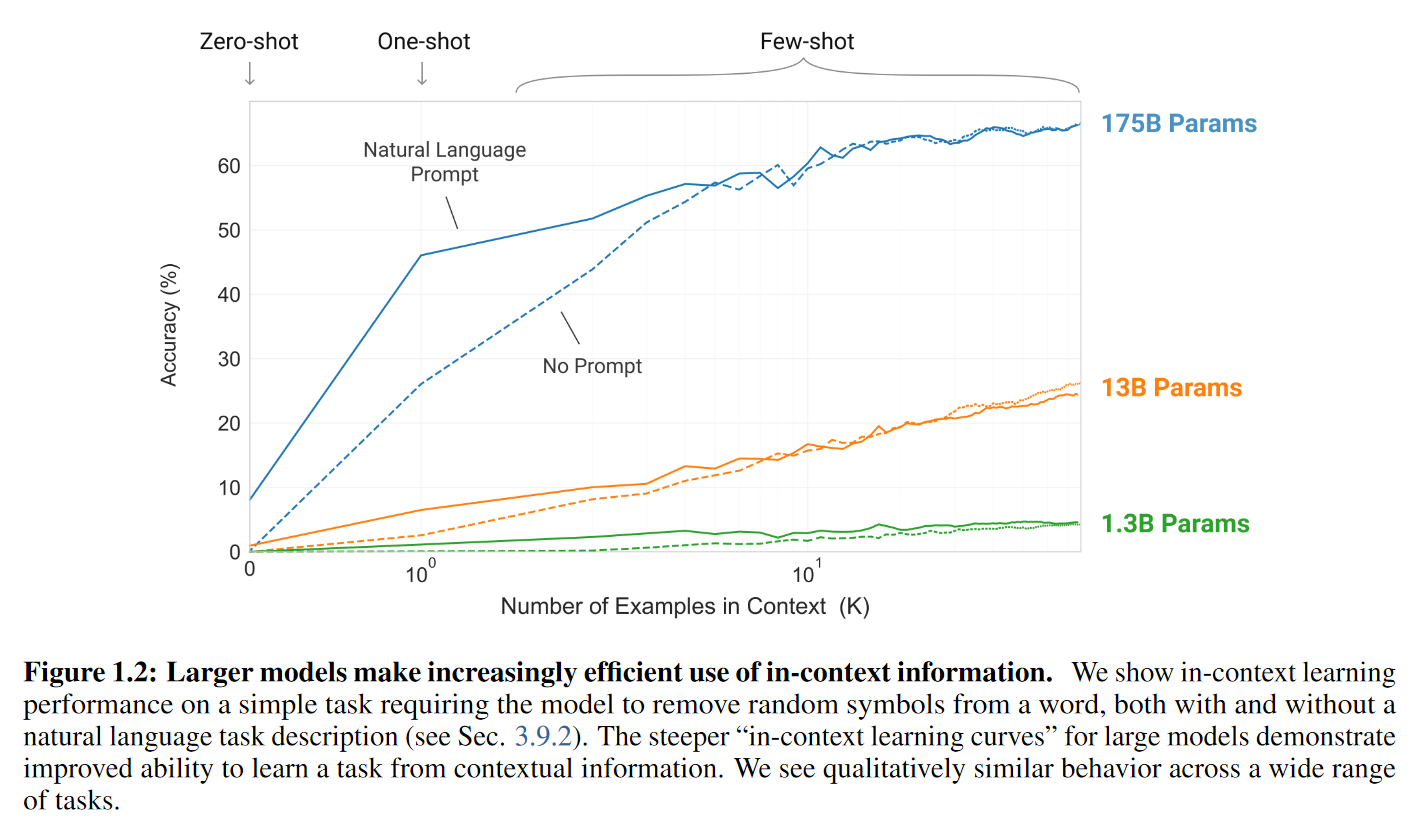
Put these two together and extrapolate, and it seems like a sufficiently large model trained on a diversity of tasks will eventually be capable of superhuman general reasoning abilities. As gwern puts it:
More concerningly, GPT-3’s scaling curves, unpredicted meta-learning, and success on various anti-AI challenges suggests that in terms of futurology, AI researchers’ forecasts are an emperor sans garments: they have no coherent model of how AI progress happens or why GPT-3 was possible or what specific achievements should cause alarm, where intelligence comes from, and do not learn from any falsified predictions.
GPT-3 is scary because it’s a magnificently obsolete architecture from early 2018 (used mostly for software engineering convenience as the infrastructure has been debugged), which is small & shallow compared to what’s possible, on tiny data (fits on a laptop), sampled in a dumb way, its benchmark performance sabotaged by bad prompts & data encoding problems (especially arithmetic & commonsense reasoning), and yet, the first version already manifests crazy runtime meta-learning—and the scaling curves still are not bending!
Still, extrapolating ML performance is problematic because it's inevitably an extrapolation of performance on a particular set of benchmarks. Lukas Finnveden, for example, argues that a model similar to GPT-3 but 100x larger could reach "optimal" performance on the relevant benchmarks. But would optimal performance correspond to an agentic, superhuman, general intelligence? What we're really interested is surprising performances in hard-to-measure domains, long-term planning, etc. So while these benchmarks might be suggestive (especially compared to human performance on the same benchmark), and may offer some useful clues in terms of scaling performance, I don't think we can rely too much on them—the error bars are wide in both directions.
Brains
The human brain is an existence proof not only for the possibility of general intelligence, but also for the existence of a process—evolution—that can design general intelligences with no knowledge of how minds operate. The brain and its evolution offer some hints about what it takes to build a general intelligence:
- Number of synapses in the brain.
- Computational power (~1e15 FLOPS/s).
- Energy consumption (~20 watts).
- Required computation for the training of individual brains.
- Required evolutionary "computation" to generate brains.
The most straight-forward comparison is synapses to parameters. GPT-3 has 1.75e11 parameters compared to ~1e15 synapses in the brain, so it's still 4 orders of magnitude off, and a model parameter is not a perfect analogue to a synapse, so this is more of an extreme lower limit rather than a mean estimate.
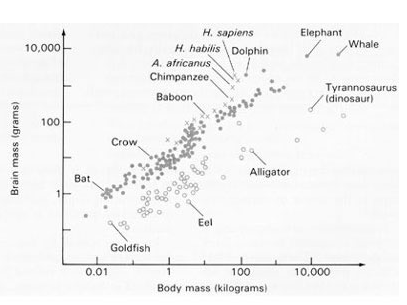
The brain also presents some interesting problems when it comes to scaling, as some aspects of human evolution suggest the scaling hypothesis might be wrong. While the human brain got bigger during the last few million years, it's only about 3-4x the size of a chimpanzee brain—compare to the orders of magnitude we're talking about in ML. On the other hand, if we look at individual differences today, brain volume and IQ correlate at ~0.4. Not a very strong correlation, but it does suggest that you can just throw more neurons at a problem and get better results.
How do we reconcile these facts pointing in different directions? Sensorimotor skills are expensive and brain size scales with body mass: whales might have massive brains compared to us, but that doesn't give them anywhere near the same intellectual capabilities. So what appears to be a relatively small increase compared to chimps is actually a large increase in brain volume not dedicated to sensorimotor abilities.
How much power will we have?
Compute use has increased by about 10 orders of magnitude in the last 20 years, and that growth has accelerated lately, currently doubling approximately every 3.5 months. A big lesson from the pandemic is that people are bad at reasoning about exponential curves, so let's put it in a different way: training GPT-3 cost approximately 0.000005%5 of world GDP. Go on, count the zeroes. Count the orders of magnitude. Do the math! There is plenty of room for scaling, if it works.
The main constraint is government willingness to fund AI projects. If they take it seriously, we can probably get 6 orders of magnitude just by spending more money. GPT-3 took 3.14e23 FLOPs to train, so if strong AGI can be had for less than 1e30 FLOPs it might happen soon. Realistically any such project would have to start by building fabs to make the chips needed, so even if we started today we're talking 5+ years at the earliest.
Looking into the near future, I'd predict that by 2040 we could squeeze another 1-2 orders of magnitude out of hardware improvements. Beyond that, growth in available compute would slow down to the level of economic growth plus hardware improvements.
Putting it all together
The best attempt at AGI forecasting I know of is Ajeya Cotra's heroic 4-part 168-page Forecasting TAI with biological anchors. She breaks down the problem into a number of different approaches, then combines the resulting distributions into a single forecast. The resulting distribution is appropriately wide: we're not talking about ±15% but ±15 orders of magnitude.
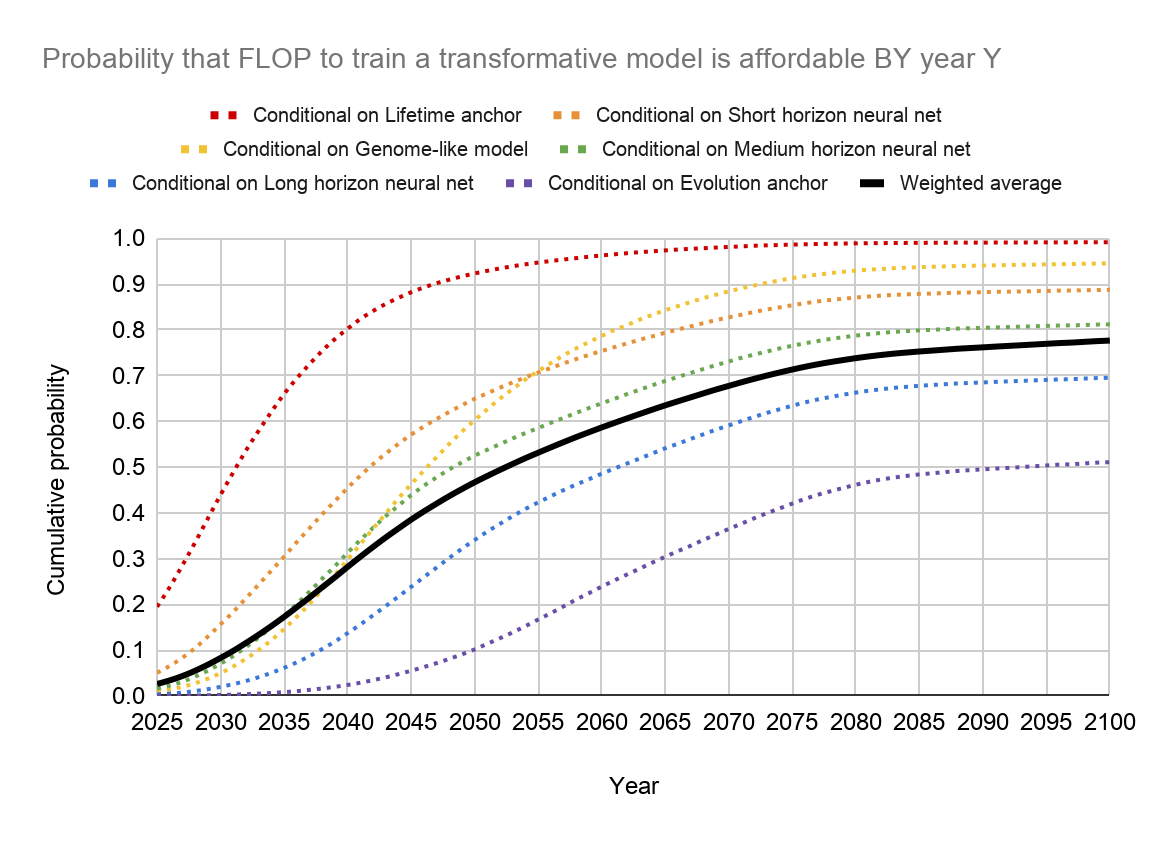
Her results can be summarized in two charts. First, the distribution of how many FLOPs it will take to train a "transformative" AI:

I highly recommend checking out Cotra's work if you're interested in the details behind each of those forecasts. This distribution is then combined with projections of our computational capacity to generate AI timelines. Cotra's estimate (which I find plausible) is ~30% by 2040, ~50% by 2050, and ~80% by 2100:
Metaculus has a couple of questions on AGI, and the answers are quite similar to Cotra's projections. This question is about "human-machine intelligence parity" as judged by three graduate students; the community gives a 54% chance of it happening by 2040. This one is based on the Turing test, the SAT, and a couple of ML benchmarks, and the median prediction is 2038, with an 83% chance of it coming before 2100. Here's the cumulative probability chart:
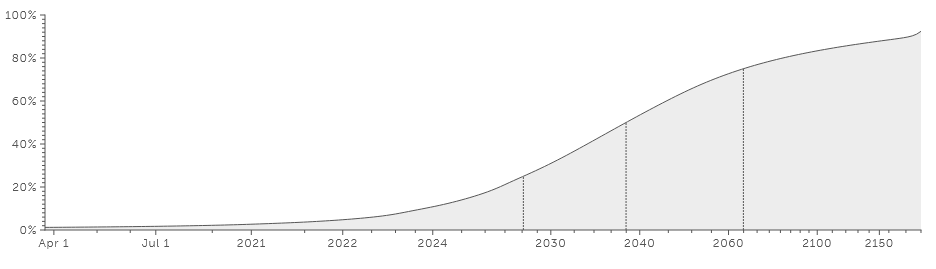
Both extremes should be taken into account: we must prepare for the possibility that AI will arrive very soon, while also tending to our long-term problems in case it takes more than a century.
Human Enhancement
All things change in a dynamic environment. Your effort to remain what you are is what limits you.
The second path to the future involves making better humans. Ignoring the AI control question for a moment, better humans would be incredibly valuable to the rest of us purely for the positive externalities of their intelligence: smart people produce benefits for everyone else in the form of greater innovation, faster growth, and better governance. The main constraint to growth is intelligence, and small differences cause large effects: a standard deviation in national averages is the difference between a cutting-edge technological economy and not having reliable water and power. While capitalism has ruthlessly optimized the productivity of everything around us, the single most important input—human labor—has remained stagnant. Unlocking this potential would create unprecedented levels of growth.
Above all, transhumanism might give us a fighting chance against AI. How likely are they to win that fight? I have no idea, but their odds must be better than ours. The pessimistic scenario is that enhanced humans are still limited by numbers and meat, while artificial intelligences are only limited by energy and efficiency, both of which could potentially scale quickly.
The most important thing to understand about the race between DNA and silicon is that there's a long lag to human enhancement. Imagine the best-case scenario in which we start producing enhanced humans today: how long until they start seriously contributing? 20, 25 years? They would not be competing against the AI of today, but against the AI from 20-25 years in the future. Regardless of the method we choose, if superhuman AGI arrives in 2040, it's already too late. If it arrives in 2050, we have a tiny bit of wiggle room.6
Let's take a look at our options.
Normal Breeding with Selection for Intelligence
Way too slow and extraordinarily unpopular.
Gene Editing
With our current technology, editing is not relevant. It's probably fine for very simple edits, but intelligence is a massively polygenic trait and would require far too many changes. However, people are working on multiplex editing, reducing the odds of off-target edits, etc. Perhaps eventually we will even be able to introduce entirely new sequences with large effects, bypassing the polygenicity problem. More realistically, in a couple of decades editing might be a viable option, and it does have the benefit of letting people have their own kids in a relatively normal way (except better).
Cyborgs
Seems unlikely to work. Even if we solve the interface problem it's unclear how a computer without superhuman general reasoning capabilities could enhance the important parts of human thought to superhuman levels. If, instead of relying on the independent capabilities of an external computer, a hypothetical brain-computer interface could act as a brain "expander" adding more synapses, that might work, but it seems extremely futuristic even compared to the other ideas in this post. Keep in mind even our largest (slowest, most expensive) neural networks are still tiny compared to brains.
Iterated Embryo Selection
The basic idea is to do IVF, sequence the embryos, select the best one, and then instead of implanting the embryo, you use its DNA for another round of IVF. Iteration adds enormous value compared to simply picking the best embryos: Shulman and Bostrom estimate that single-stage selection of 1 in 1000 embryos would add 24.3 IQ points on average. On the other hand, 10 generations of 1-in-10 selection would add ~130 points. On top of the IQ gains we could also optimize other traits (health, longevity, altruism) at the same time. This is the method with the highest potential gains, as the only limit would be physiological or computational. And IES wouldn't be starting at 100: if we use Nobel laureates, we've already got ~3 SDs in the bag.
How far can IES go? There are vast amounts of variation for selection to work on, and therefore vast room for improvement over the status quo. Selection for weight in broiler chickens has resulted in rapid gain of 10+ standard deviations, and I believe we can expect similar results for selection on intelligence. Chicken size is probably not a perfect parallel to intelligence, and I'm sure that eventually we will start hitting some limits as additivity starts to fail or physical limitations impose themselves. But I don't think there are any good reasons to think that these limits are close to the current distribution of human intelligence.
However, there are some problems:
- IVF is expensive and has a low success rate.
- Gametogenesis from stem cells isn't there yet (but people are working on it).
- Sequencing every embryo still costs ~$500 and our PGSs7 aren't great yet.
- The process might still take several months per generation.
None of these are insoluble. Sequencing costs are dropping rapidly, and even with today's prices the costs aren't that bad: gwern estimates $9k per IQ point. He says it's expensive, but it would be very easily worth it from a societal perspective. The biggest downside is the time it would take: say 5 years to make IES tech viable, another 5 years for 10 rounds of selection,8 and we're at 2050 before they're grown up. Still, it's definitely worth pursuing, at the very least as a backup strategy. After all there's still a good chance we won't reach superhuman AGI by 2050.
How likely is any of this to happen? Metaculus is very pessimistic even on simple IVF selection for IQ, let alone IES, with the median prediction for the first 100 IQ-selected babies being the year 2036. Here's the cumulative probability chart:
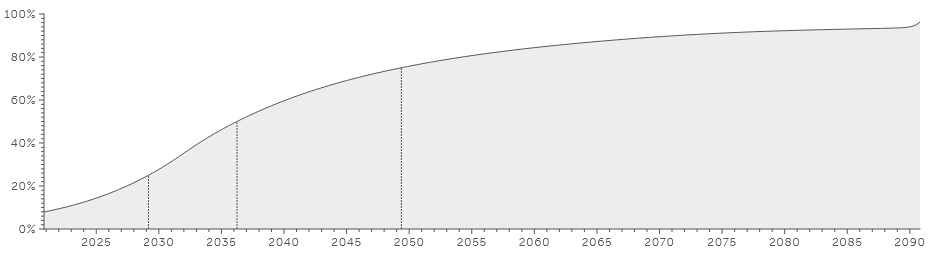
That seems late to me. Perhaps I'm underestimating the taboo against selecting on IQ, but even then there's a whole world out there, many different cultures with fewer qualms. Then again, not even China used human challenge trials against covid.
Cloning
I believe the best choice is cloning. More specifically, cloning John von Neumann one million times.9 No need for editing because all the good genes are already there; no need for long generation times because again, the genes are already there, just waiting, chomping at the bit, desperately yearning to be instantiated into a person and conquer the next frontiers of science. You could do a bunch of other people too, diversity of talents and interests and so on, but really let's just start with a bunch of JvNs.10
Why JvN? Lots of Nobel laureates in physics were awed by his intelligence (Hans Bethe said his brain indicated "a species superior to that of man"). He was creative, flexible, and interested in a fairly wide array of fields (including computing and artificial intelligence).11 He was stable and socially competent. And he had the kind of cosmic ambition that we seem to be lacking these days: "All processes that are stable we shall predict. All processes that are unstable we shall control." As for downsides: he died young of cancer,12 he was not particularly photogenic, and he loved to eat and thought exercise was "nonsense".
There are commercial dog- and horse-cloning operations today. We've even cloned primates. The costs, frankly, are completely trivial. A cloned horse costs $85k! Undoubtedly the first JvN would cost much more than that, but since we're making a million of them we can expect economies of scale. I bet we could do it for $200 billion, or less than half what the US has spent on the F35 thus far. Compared to the predicted cost of training superhuman AGI, the cost of one million JvNs is at the extreme lower end of the AI forecasts, about 5 orders of magnitude above GPT-3.
Let's try to quantify the present value of a JvN, starting with a rough and extremely conservative estimate: say von Neumann had an IQ of 18013 and we clone a million of them. Due to regression to the mean, the average clone will be less intelligent than the original; assuming heritability of .85, we'd expect an average IQ of 168. This would increase average US IQ by 0.21 points. Going by Jones & Schneider's estimate of a 6% increase in GDP per point in national IQ, we might expect about 1.26% higher output. If the effect was immediate, that would be about $270 billion per year, but we should probably expect a few decades before it took effect. Even this extremely modest estimate puts the value of a JvN at about $270k per year. Assuming the JvNs become productive after 20 years, affect GDP for 50 years, 2% GDP growth, and a 3% discount rate, the present value of a JvN is around $8.4 million. The cost:benefit ratio is off the charts.14
However, I think this is a significant under-estimate. Intuitively, we would expect that governance and innovation are more heavily influenced by the cognitive elite rather than the mean. And there is decent empirical evidence to support this view, generally showing that the elite is more important. As Kodila-Tedika, Rindermann & Christainsen put it, "cognitive capitalism is built upon intellectual classes." One problem with these studies is that they only look at the 95th percentile of the IQ distribution, but what we really care about here is the 99.9th percentile. And there are no countries with a million 170+ IQ people, so the best we can do is extrapolate from slight deviations from the normal distribution.
Another piece of evidence worth looking at is Robertson et al.'s data on outcomes among the top 1% within the US. They took boys with IQs above the 99th percentile and split them into four groups (99.00-99.25th percentile, etc.), then looked at the outcomes of each group:
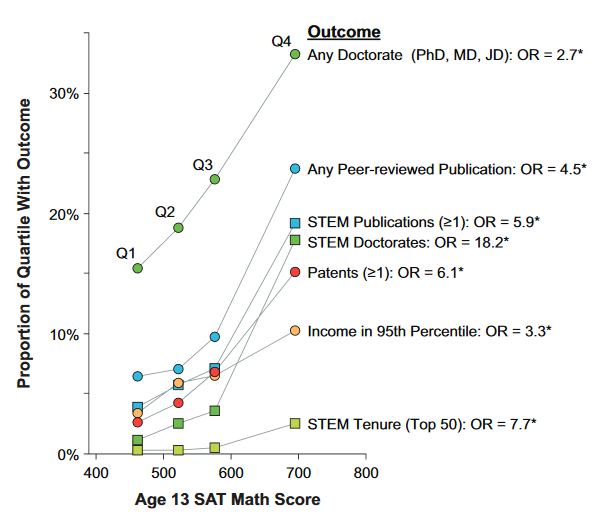
Simply going from an IQ of ~135 (99th percentile) to ~142+ (99.75th percentile) has enormous effects in terms of income, innovation, and science. Extrapolate that to 168. Times a million. However, the only variable here that's directly quantifiable in dollar terms is >95th percentile income and what we're really interested in are the externalities. Undoubtedly the innovation that goes into those patents, and the discoveries that go into those publications create societal value. But putting that value into numbers is difficult. If I had to make a wild guess, I'd multiply our naïve $8.4 million estimate by 5, for a present value of $42 million per JvN.
That is all assuming a permanent increase in the level of output. A more realistic estimate would include faster growth. Beyond the faster growth due to their discoveries and innovations, the JvNs would also 1) help make genetic enhancement universal (even light forms like single-stage embryo selection would increase world GDP by several multiples) and, most importantly, 2) accelerate progress toward superhuman AI, and (hopefully) tame it. To take a wild guess at how much closer the JvNs would bring us to AGI: they would give us an order of magnitude more in spending, an order of magnitude faster hardware, and an order of magnitude better training algorithms, for a total increase in effective computational resources of 1000x. Here's how Cotra's average AI timeline would be accelerated, assuming the JvNs deploy that extra power between 2045 and 2055:
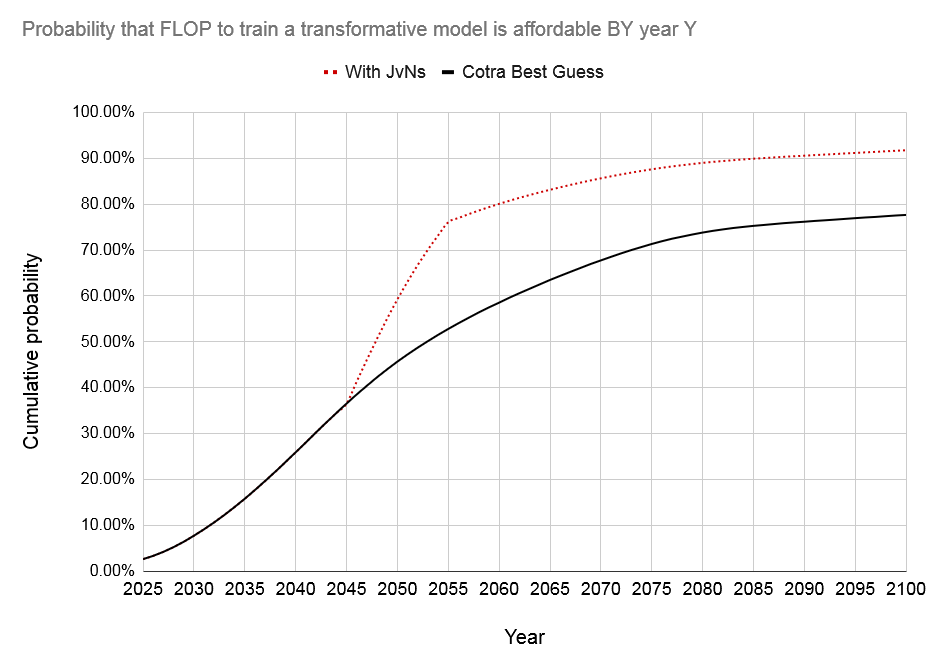
US GDP growth has averaged about 2.9% in the 21st century; suppose the JvNs triple the growth rate for the rest of the century:15 it would result in a cumulative increase in output with a present value of approximately $9 quadrillion, or $9 billion per JvN.16
At a time when we're spending trillions on projects with comically negative NPV, this is probably the best investment a government could possibly make. It's also an investment that will almost certainly never come from the private sector because the benefits are impossible to capture for a private entity.
Would there be declining marginal value to JvNs? It seems likely, as there's only so much low-hanging fruit they could pick before the remaining problems became too difficult for them. And a JvN intellectual monoculture might miss things that a more varied scientific ecosystem would catch. That would be an argument for intellectual diversity in our cloning efforts. Assuming interests are highly heritable we should probably also re-create leading biologists, chemists, engineers, entrepreneurs, and so on.17 On the other hand there might be o-ring style network effects which push in the opposite direction. There's also a large literature on how industrial clusters boost productivity and create economies of scale; perhaps there are such clusters in scientific output as well.
As for the problems with this idea: human cloning has about the same approval rating that Trump has among Democrats.18 We can expect the typical trouble with implanting embryos. We would need either artificial wombs or enough women willing to take on the burden. And worst of all, unlike IES, cloning has a hard upside limit.
A Kind of Solution
I visualise a time when we will be to robots what dogs are to humans, and I’m rooting for the machines.
Let's revisit the AI timelines and compare them to transhumanist timelines.
- If strong AGI can be had for less than 1e30 FLOPs, it's almost certainly happening before 2040—the race is already over.
- If strong AGI requires more than 1e40 FLOPs, people alive today probably won't live to see it, and there's ample time for preparation and human enhancement.
- If it falls within that 1e30-1e40 range (and our forecasts, crude as they are, indicate that's probable) then the race is on.
Even if you think there's only a small probability of this being right, it's worth preparing for. Even if AGI is a fantasy, transhumanism is easily worth it purely on its own merits. And if it helps us avoid extinction at the hand of the machines, all the better!
So how is it actually going to play out? Expecting septuagenarian politicians to anticipate wild technological changes and do something incredibly expensive and unpopular today for a hypothetical benefit that may or may not materialize decades down the line—is simply not realistic. Right now from a government perspective these questions might as well not exist; politicians live in the current paradigm and expect it to continue indefinitely. On the other hand, the Manhattan Project shows us that immediate existential threats have the power to get things moving very quickly. In 1939, Fermi estimated a 10% probability that a nuclear bomb could be built; 6 years later it was being dropped on Japan.
My guess is that some event makes AI/transhumanism (geo)politically salient, which will trigger a race between the US and China, causing an enormous influx of money.19 Perhaps something like the Einstein–Szilárd letter, perhaps some rogue scientist doing something crazy. Unlike the Manhattan Project, in today's interconnected world I doubt it could happen in secret: people would quickly notice if all the top geneticists and/or ML researchers suddenly went dark. From a geopolitical perspective, He Jiankui's 3 year jail sentence might be thought of as similar to Khrushchev removing the missiles from Cuba: Xi sending a message of de-escalation to make sure things don't get out of hand. Why does he want to de-escalate? Because China would get crushed if it came to a race between them and the US today. But in a decade or two? Who knows what BGI will be capable of by then. It's probably in the West's interests to make it happen ASAP.
This all has an uncomfortable air of "waiting for the barbarians", doesn't it? There's a handful of people involved in immanentizing the eschaton while the rest of us are mere spectators. Are we supposed to twiddle our thumbs while they get on with it? Do we just keep making our little flint blades? And what if the barbarians never arrive? Maybe we ought to pretend they're not coming, and just go on with our lives.20
The race to the future is not some hypothetical science fiction thing that your grand-grand-grandkids might have to worry about. It's on, right now, and we're getting creamed. In an interview about in vitro gametogenesis, Mitinori Saitou said “Technology is always technology. How you use it? I think society probably decides.” Technology is always technology, but the choice is illusory. What happened to stone age groups that did not follow the latest innovations in knapping? What happened to groups that did not embrace bronze? The only choice we have is: up, or out. And that is no choice at all.
- 1.Meyer & Vallée, The Dynamics of Long-Term Growth. ↩
- 2.I also suspect that enslaving God is a bad idea even if it works. ↩
- 3.It comes down to hardware improvements and economic resources, two variables that are highly predictable (at least over the near future). ↩
- 4."But Alvaro, I don't believe we will build AGI at all!" I can barely tell apart parodies from "serious" anti-AI arguments any more. There's nothing magical about either meat or evolution; we will replicate their work. If you can find any doubters out there who correctly predicted GPT-3's scaling and meta-learning performance, and still doubt, then I'd be interested in what they have to say. ↩
- 5.How much could we spend? 0.5% per year for a decade seems very reasonable. Apollo cost about ~0.25% of US GDP per year and that had much more limited benefits. ↩
- 6.This is all predicated on the supposition that enhanced humans would side with humanity against the machines—if they don't then we're definitely no more than a biological bootloader. ↩
- 7.Polygenic score, a measure of the aggregate effect of relevant genetic variants in a given genome on some phenotypic trait. ↩
- 8.Alternatively we could start implanting from every generation on a rolling basis. ↩
- 9.If you can do it once there's no reason not to do it at scale. ↩
- 10.And maybe a few hundred Lee Kuan Yews for various government posts. ↩
- 11.He may even have been the first to introduce the idea of the technological singularity? Ulam on a conversation with JvN: "One conversation centered on the ever accelerating progress of technology and changes in the mode of human life, which gives the appearance of approaching some essential singularity in the history of the race beyond which human affairs, as we know them, could not continue." ↩
- 12.Might not be genetic though: "The cancer was possibly caused by his radiation exposure during his time in Los Alamos National Laboratory." ↩
- 13.That's about 1 in 20 million. ↩
- 14.Should we expect a million von Neumanns to affect the level or growth rate of GDP? Probably both, but I'm trying to keep it as simple and conservative as possible for now. ↩
- 15.A metaculus question on the economic effects of human-level AI predicts a 77% chance of >30% GDP growth at least once in the 15 years after the AI is introduced. ↩
- 16.Of course this ignores all the benefits that do not appear in GDP calculations. Technology, health, lack of crime, and so on. Just imagine how much better wikipedia will be! ↩
- 17.No bioethicists though. ↩
- 18.How much of this is driven by people averse to rich people selfishly cloning themselves? Perhaps the prosocial and rather abstract idea of cloning a million von Neumanns would fare better. One clone is a tragedy; a million clones is a statistic. ↩
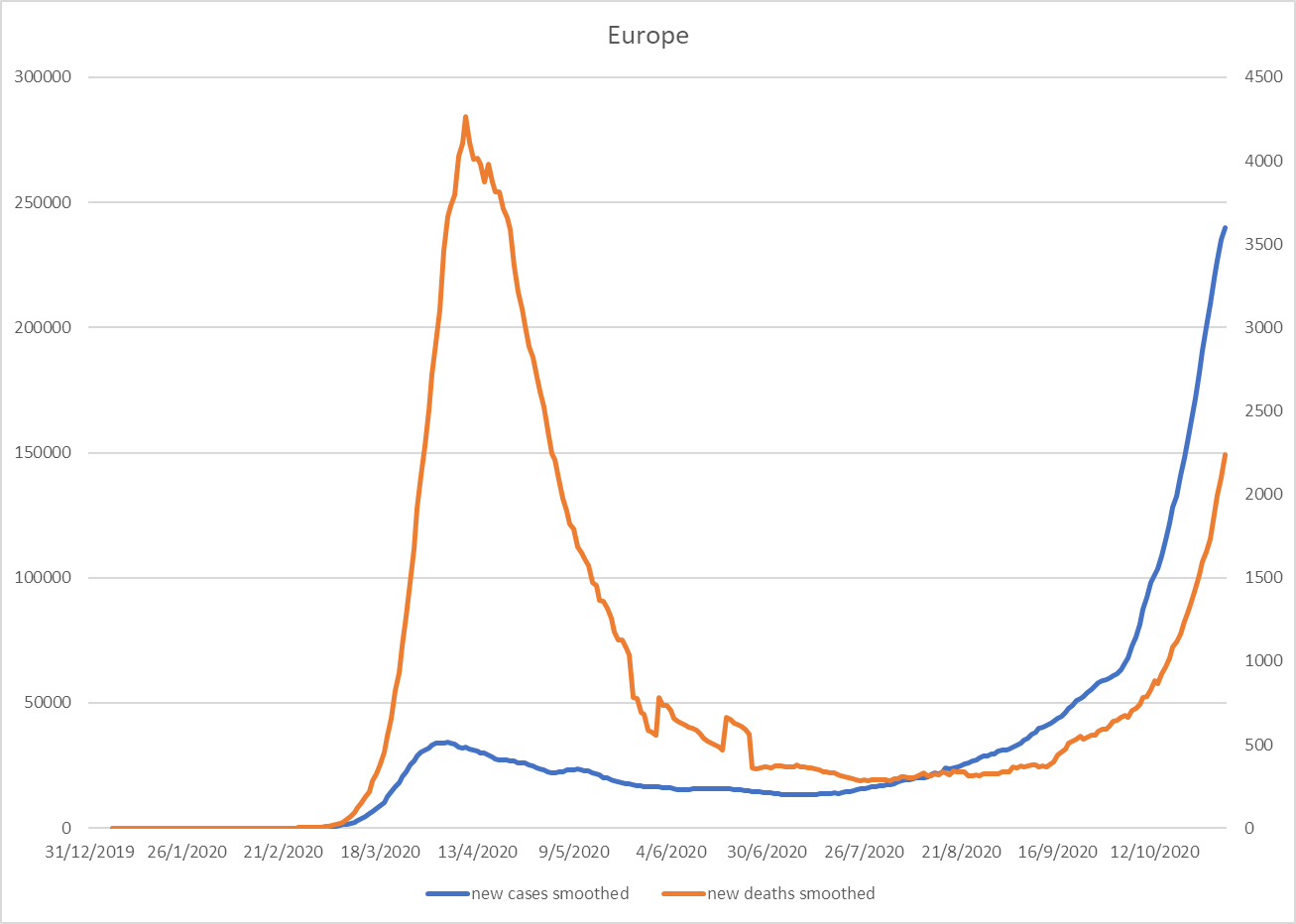
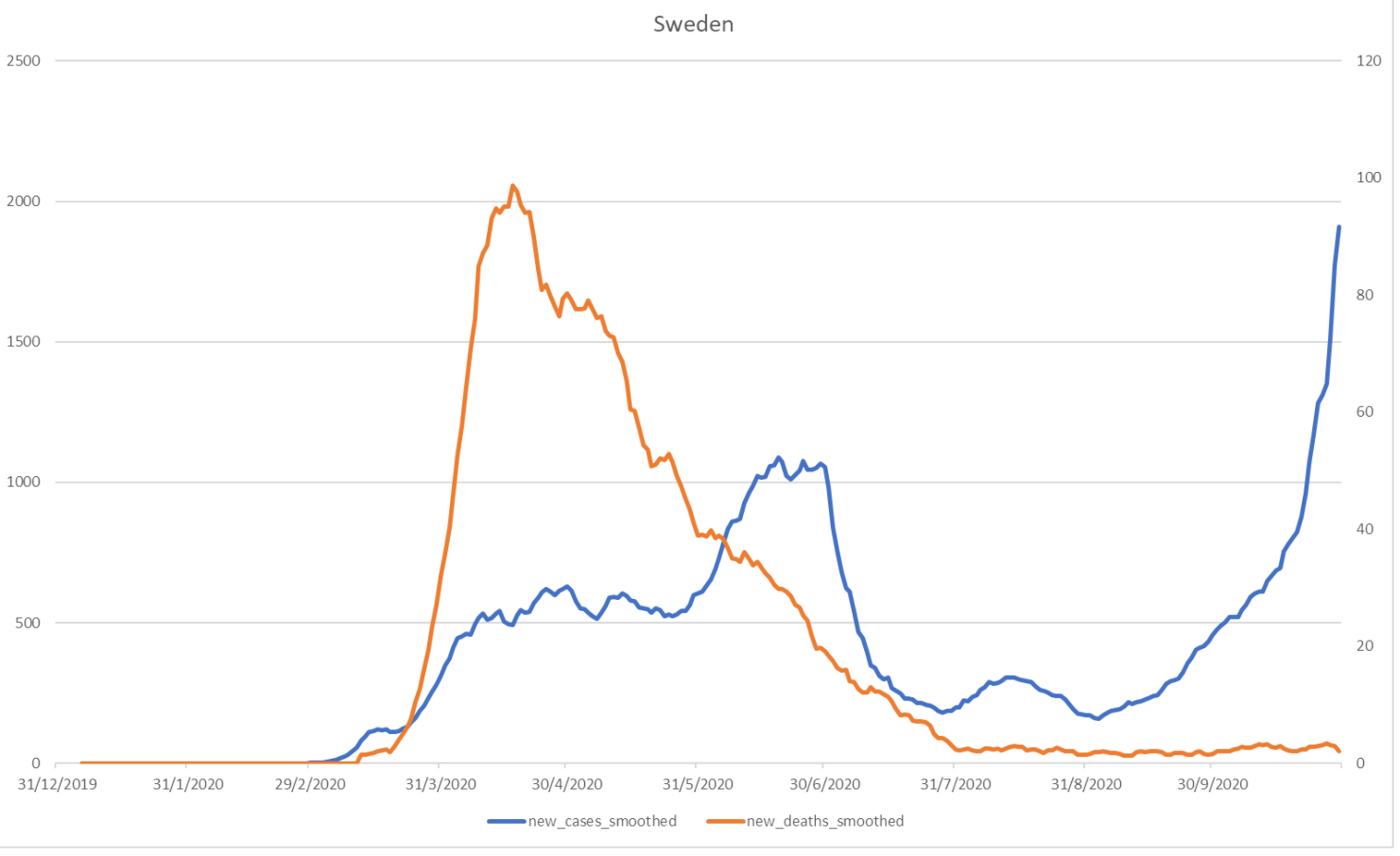
- 19.Europe is (of course) not even a player in this game. I wouldn't trust Mutti Merkel and her merry band of eurocrats to boil a pot of water let alone operate a transhumanist program. ↩
- 20.In Disco Elysium the world is quickly being destroyed by a supernatural substance known as the "pale": they don't know how much time they have left, but it's on the order of a few decades. Everyone goes on with their petty squabbles regardless. The more I think about it, it seems like less of a fantasy and more of a mirror. How long until the last generation? ↩